嗨,你好,我是維元 👋 我會持續分享我在資料科學與人工智慧領域所觀察到的趨勢與所見所聞 💥 模型越來越強,但真正能不能落地,反而不是看模型本身,而是看「你能不能讓它用到對的資訊」。而這正是 RAG(Retrieval-Augmented Generation)存在的理由。
RAG 不會提升模型的能力,但會大幅提升「應用」的品質與可控性。
很多人以為 RAG 是讓模型變聰明,但事實正好相反。RAG 並不能提升模型的推理能力、邏輯深度,也無法增強它的固有技能。RAG 做的是一件更務實的事:讓模型「用到它沒讀過的知識」,就像為大型語言模型外掛上一個資料庫一樣。在企業應用中,AI 的瓶頸往往不是「模型太笨」,而是「模型不知道我們公司的事」;文件放哪?流程怎麼走?規範是什麼?最新版本是什麼?內部名詞代表什麼?這些都是模型不知道、也學不來、也不該硬記的東西。因此,RAG 的價值在於提升模型的「可靠度」與「可控性」,補上真實世界的落地斷層。

🎯 RAG 並不會讓模型更聰明,但它會讓模型變得「可用」
RAG 不會提升模型的邏輯能力、推理深度,也不會讓模型變得更像 GPT-5 或 Gemini Pro。它做的事情比較務實 —— 讓模型知道你希望它知道的事情。
企業真正的難題通常不是模型不夠聰明,而是模型「不知道我們的東西」:
– SOP 怎麼走?
– 文件最新版本是哪份?
– 法規更新到哪一條?
– 公司內部名詞是什麼意思?
– 舊系統的錯誤碼對應什麼流程?
這些資訊模型不會記得,也不該硬記。RAG 的角色就是一座橋,把「模型的世界」接上「真實的知識世界」。
它讓回應更可靠、可控、可追蹤,讓模型不再失控亂講,而是真正能配合企業知識產生答案。
換句話說:
👉 RAG 不強化模型,但強化 AI「落地的可能性」。
當代的 RAG(Retrieval-Augmented Generation)主要用來解決 LLM 的四個不足👇
- ➀ 冷門領域知識不足
- ➁ 容易產生幻覺(hallucination)
- ➂ 無法即時更新資料
- ➃ 涉及機密時的資料隱私
LLM 預訓練的權重就像「長期記憶」,上下文能提供「短期記憶」,而 RAG 就是外掛一個「知識查詢器」。舉個例子:LLM 像一座藏書無數的圖書館,但你找不到書、讀不完書、也記不住書。RAG 就像聰明的圖書館管理員,幫你在最短時間內打開「那幾頁你真的需要的內容」。
💡 那「無限上下文」能取代 RAG 嗎?
理論上可以,但代價極高;Token 用量、推理時間都會造成模型成本爆炸;而且根據經驗上下文增加的情況下會造成模型的準確度下降,也就是說: 能看完 ≠ 能理解,能記住 ≠ 能推理 ☻
🧩 常見的 RAG 作法與優化策略
RAG 系統不只是一種方法,而是一整套工程技巧的集合。最基礎的 Naive RAG——把文件切 chunk、建 embedding、丟進向量資料庫、top-k 召回——雖然簡單,但也是最多人卡關的地方。只要 chunk 切不好、embedding 不準、召回沒中,後續生成的答案就會偏掉,甚至「越補越錯」。這也是為什麼許多人做出來的 RAG 效果很差,明明流程看似正確,但實務上卻完全不可靠。
最原始的 Naive RAG —— chunk → embedding → vector search → top-k → 丟給模型 —— 看起來很簡單,但也是大多數人做出「效果不行的 RAG」的原因。
為什麼?因為只要檢索一歪,模型就會用錯資訊作答,導致「越補越錯」。
所以進階的 RAG,都在想方設法「讓檢索更準」:
技巧 ① 拼接對的資訊,讓語言模型找到真正有用的知識
RAG 的核心在於「檢索要準」。如果模型看到錯的上下文,就算推理再強也會得出錯的結論。因此,讓查詢變得「可檢索」、讓模型更容易找到真正關鍵的資訊,是 RAG 優化的第一步。
其中兩個方法最常見、也最有效:Query Rewrite 與 HyDE。Query Rewrite 會先將使用者模糊、跳躍、資訊不足的問題,改寫成向量搜尋更容易命中的版本;HyDE 則讓模型先生成一份「假想答案」,再用這段答案的 embedding 去找實際存在的內容。兩者都能在資訊抽象、敘述不清、需要多階段推理的任務中明顯提升命中率。
- Query Rewrite: 先把使用者問題改寫成「可檢索的版本」。
- HyDE: 讓模型先生成「假想答案」,再用其 embedding 來找更相關的文件。
技巧 ② 從哪裡找?該怎麼找?讓檢索變得更聰明
許多人以為 RAG 效果不好,是因為「沒有找到正確的文件」。但真實原因往往剛好相反:找到的文件太多、太雜、不夠相關,卻全被塞給模型。這會嚴重稀釋上下文訊號,讓模型迷失方向。
因此,提升檢索品質最有效的方法之一,就是加入 Rerank。Cross-Encoder Reranker 能根據語義相關度重新排序所有 chunk,確保模型最先看到真正重要的上下文,大幅提升答案品質。
另一個常被忽略但非常強大的技巧,是讓每個 chunk 不再只有單一 embedding,而是具備多視角表示:摘要、標題、QA、關鍵字。這樣的 Multi-Vector Retrieval 讓系統能從不同角度命中同一份資訊,對多樣化查詢特別有效。
- Rerank: 以 Cross-Encoder 重新排序檢索結果,大幅提升準度。
- 多向量檢索: 每個 chunk 擁有「摘要+標題+QA+關鍵詞」等多種 embedding,強化命中率。
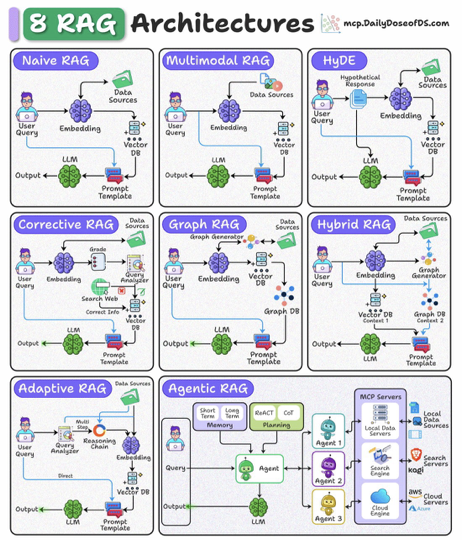
技巧 ③ RAG 的變形:從 Graph RAG 到 Agentic RAG
當任務更加複雜,如組織架構查詢、法規引用、多跳推理等,傳統向量搜尋就不夠力了。這時 Graph RAG 就顯得重要:它將原始知識圖結構化,讓模型可以「沿著關係走路」,並理解節點之間的因果與依存關係,使 multi-hop 推理更穩定,也更不容易幻覺。
但 2025 之後,RAG 的進化方向將不再只是提高檢索品質,而是讓系統具備「思考」能力。這就是 Agentic RAG。
Agentic RAG 不再只是單純查資料,而是讓模型能主動判斷:
要不要檢索?要如何檢索?是否需要多步檢索?需不需要改寫查詢?是否要調用外部 API?是否應該補上下文?
它不再是被動的 Retrieval,而是具有策略思維的 Retrieval Planner。
這標誌著一個重要轉變:RAG 從被動工具,進化成主動的智慧系統。
除此之外,還有各種常見的變形,但實際上哪個好用、該怎麼選不一定有一個標準的答案
⚖️ RAG 與 Fine-Tune 的比較:到底什麼時候用哪個?
企業在導入 AI 時最常問的一句話是:「我們該做 RAG 還是 fine-tune?」如果要一句話講清楚 —— RAG 補的是『知識』,Fine-Tune 補的是『技能』。
#先說結論:RAG 補的是「知識」,Fine-Tune 補的是「技能」。
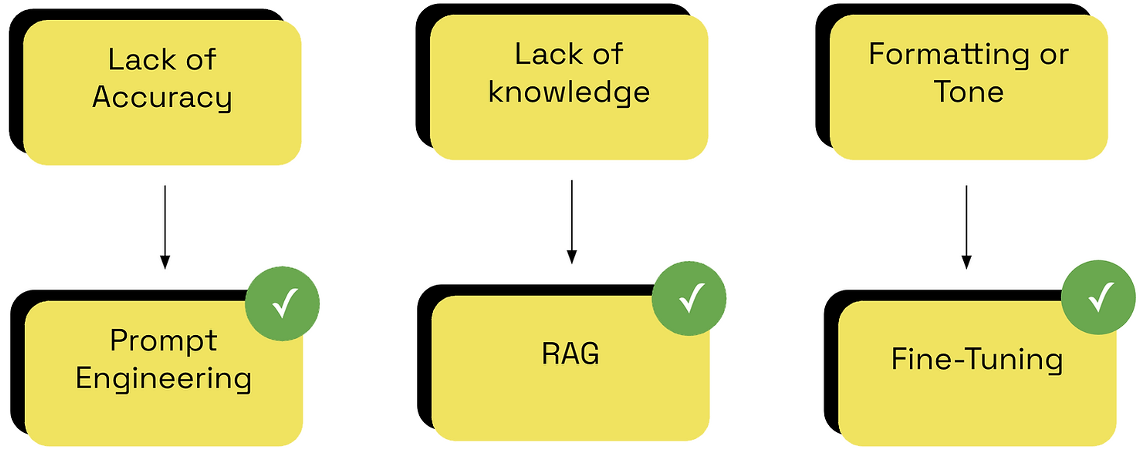
RAG 適合處理大量文件、需要精準引用、需要動態更新內容的場景;它讓模型「知道公司知道的事」。Fine-Tune 則適合格式嚴謹、風格一致、任務導向明確的情境,例如法條摘要、病歷結構化、客服應答格式化、專業語氣模仿,它讓模型「學會某種任務」。而 Prompt Engineering 則補上策略層面的不足,讓模型的思考方式較符合任務需求。
📌 RAG 的適用場景
需要引用文件、答案依賴最新資料、內容常更新、需可追溯來源的情境,例如:
– SOP / FAQ 問答
– 法規、財報、產品手冊
– 醫療、教育、企業內部知識庫
📌 Fine-Tune 的適用場景
需要模型模仿「格式、風格、流程」並穩定生成的任務,例如:
– 法條摘要
– 報表結構化
– 客服應答格式
– 科技專業寫作風格
真正成熟的 AI 產品一定不是三選一,而是三者融合:
Prompt → RAG → Fine-Tune
各補一塊短板,最後拼成能上線、能維護、能演化的 AI 系統。
🏁 結語:RAG 不是魔法,但它是 AI 產品從 Demo 到產品的關鍵一步
RAG 不會讓模型變聰明,但會讓它變可靠;不會提升 IQ,但能提升答案品質;不會讓模型變超人,但會讓它變成企業真正能用的工具。模型是大腦,RAG 是記憶體,Fine-Tune 是技能,而真正能被使用的 AI 產品,就是這三者的協作。RAG 不會讓模型變超人,但會讓它變「真正能用」。
AI 產品真正的價值是讓「模型能不能用到正確的東西」,而 RAG 正是讓 LLM 接上真實世界的那個外掛。
License

本著作由Chang Wei-Yaun (v123582)製作,
以創用CC 姓名標示-相同方式分享 3.0 Unported授權條款釋出。